Сложность схемы базы данных и запутанность настроек программы, созданной для этой базы, примерно одинаковы. Однако всегда сложнее понять чужие мысли, чем изложить свои собственные самому себе. Поэтому вы создадите схему базы-для-себя быстрее, чем представите карту взаимосвязей чужих настроек [1]. И если бы на весах лежали только схема и карта, понятно что бы вы предпочли.
Что же заставляет нас выбирать плохое решение, да еще и платить за него? Какую третью гирю мы должны сбросить с первой чаши, чтобы обрести сразу двойную выгоду? Мы должны сбросить программирование - или редуцировать его в максимальной степени.
Это возможно, если обратить внимание на одну тонкость - поля вывода связаны отношениями IDEF1. Экран программы имеет схему, и эта схема полностью повторяет схему базы данных!
Например, если мы выводим сотрудников какого-либо департамента

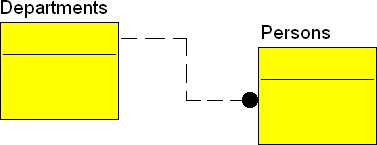
Вместо того, чтобы вставить теряемую информацию машиной, мы пытаемся сделать это вручную, заставляя человека трассировать работу компьютера. На это уходит до 50% рабочего времени. Трассировка записывается в нотации LOOP/FETCH. Мы извлекаем по одной записи для того, чтобы найти связанные с нею. И эта проблема до сих пор не отрефлексирована индустрией.
Сильное решение есть. Это выражения вида "SELECT * FROM Departments.Persons" [2]. Развитие этой идеи представлено в разделе " Hierarchical input-output (hIO) " отдельного pdf-документа (с.5-77). В тот момент, когда мы сможем отразить схему базы данных на схему экрана минуя ручную трассировку, мы сможем писать личное ПО.
[2] О чем автор уже вскользь упоминал между решениями 2-й и 3-й проблем в предыдущей статье. Кроме того, департаменты и персоны могут быть связаны не напрямую, а через таблицу-посредник, например таблицу "Sections" - тогда упомянутый запрос будет выглядеть так (с.23 pdf-документа)
select Departments.Persons from Departments.Sections.Persons where Departments/@name="E-banking";
Тюрин Дмитрий, dmitryturin@yandex.ru